2018, ça fait 5 ans que le terme « Big Data » est dans le dictionnaire Oxford. Bien sûr, ça ne fait pas 5 ans que les mégadonnées existent (Google traitait déjà 20 pétaoctets de données par jour en 2008), mais les pratiques d’analyse qui entourent le phénomène sont encore relativement jeunes. La technologie Hadoop existe depuis 2005, mais n’est devenue vraiment accessible et grand public il n’y a que quelques années. Où en sommes-nous à ce jour au Canada?
Avant d’aller plus loin, regardons quelques chiffres de la nouvelle étude 2018 sur les enjeux en matière de technologie de l’information de NOVIPRO et Léger. Cette dernière nous apprend que 75 % des décideurs au Canada ont l’intention d’utiliser des données pour faire de l’analyse prédictive. Qui dit analyse prédictive dit généralement une forme de Big Data. Ces mêmes décideurs semblent avoir l’intention de déployer des solutions pour continuer à transformer leurs entreprises à 46 % de l’intelligence d’affaire, à 27 % de l’intelligence artificielle, à 26 % des solutions Internet des objets et à 25 % de l’apprentissage machine.
Les grandes entreprises mènent le bal
On s’en doute, qui dit mégadonnées dit méga-producteurs de données. Ceux qui produisent de la donnée sont bien sûr les grands joueurs de la banque et l’assurance, des télécommunications, de l’industrie pharmaceutique, du jeu vidéo, du commerce de distribution multicanale, etc. C’est logique étant donné qu’ils produisent et stockent des données depuis des dizaines d’années, il ne suffit donc que de les analyser pour en extraire de la valeur.
Au Québec, les initiatives de type Big Data en sont généralement à leurs balbutiements. Les grandes entreprises sont soit encore en phase de démonstration de faisabilité (proof of concept), soit en production, mais généralement à petite et moyenne échelle, c’est-à-dire sur un domaine d’affaires limité où l’utilisation est restreinte à une activité précise : la prévention de la fraude, la segmentation client, l’analyse de parcours, etc. C’est donc des niveaux de maturité plutôt faibles comparés aux géants américains, mais c’est déjà un pas dans la bonne direction.
La situation semble plus mature en Ontario. Il suffit de faire une recherche sur un site d’emploi pour s’apercevoir qu’il y a beaucoup plus d’offres à Toronto qu’à Montréal; tous types de postes confondus (management, développement, ventes, etc.). Le terme « full stack developer » est utilisé à titre de base de comparaison.
Nombre d'offres d'emploi affichées par mots clés et par provinces (janvier 2018)
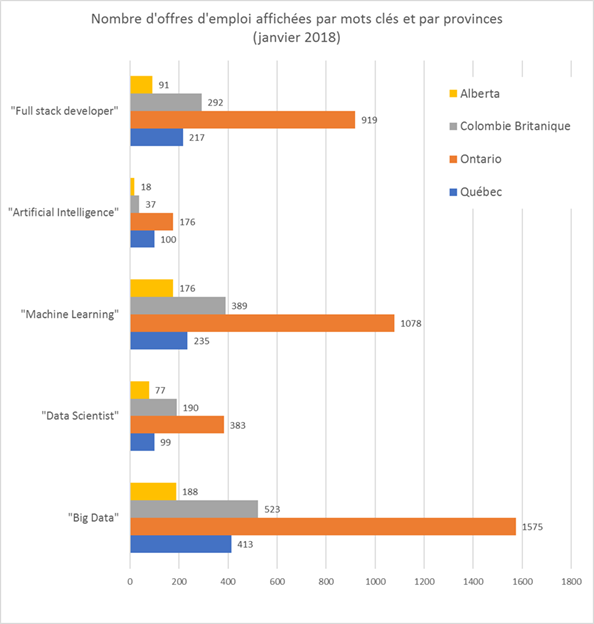

Source des données : indeed.ca
En cherchant sur des mots clés tels que « Big Data » et « Artificial Intelligence », on peut grossièrement se faire une idée de la vigueur du marché pour les domaines de l’écosystème des mégadonnées et l’on s’aperçoit que c’est très actif dans la région de Toronto. La différence s’explique fort probablement par une plus grande présence de sièges sociaux nationaux dont notamment ceux des grandes banques qui sont friandes d’IA. Dans le secteur public, le domaine de l’analyse de mégadonnées est difficile à évaluer, mais il en est probablement aux balbutiements, un peu comme le reste du marché. Quelques ministères semblent s’ouvrir à de nouvelles pratiques plus « modernes », mais pour l’instant il n’y a pas d’écho sur les pratiques entourant le Big Data. Il ne serait cependant pas surprenant que les services de renseignement canadiens ou l’armée mijotent quelque chose dans leur coin. Finalement, le même type de recherche entre le Canada et les États-Unis démontre que le marché est plus actif avec un taux d’offres d’emploi par 100 000 habitants plus élevé au sud de la frontière.
Nombre d'offres d'emploi affichés par mots clés, par 100 000 habitants (janvier 2018)
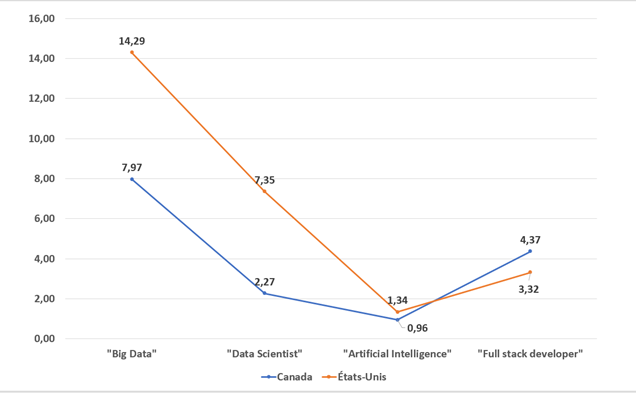
Source des données : indeed.ca et indeed.com
C’est près de deux fois plus d’emplois per capita dans le secteur du « Big Data » et plus de trois fois le nombre d’emplois pour des scientifiques de données, bien que le terme soit généralement galvaudé. Fait intéressant, il n’y a pas beaucoup plus d’emplois aux États-Unis pour ce qui est de l’intelligence artificielle. Ce qui pourrait expliquer le phénomène est le fait qu’étant un domaine encore nouveau, les emplois sont généralement hautement spécialisés et dans le domaine de la recherche. Les entreprises ne sont donc pas encore au point de recruter massivement des experts de l’intelligence artificielle.
Les PME plus ou moins intéressées
Selon Statistique Canada, près de 90 % de la population travaillait pour une petite ou moyenne entreprise en 2015.[1] Il ne faudrait pas toutes les mettre dans le même bateau, mais ce qui a été observé est que malgré un intérêt certes présent pour les mégadonnées, celles qui passent à l’action sont plutôt rares. Bien sûr, cela dépend toujours du domaine d’activité de l’entreprise et de l’appétence technologique des gestionnaires, mais l’on observe pour l’instant de belles initiatives informatiques sur des outils qui aident au jour le jour les activités d’une entreprise : des progiciels, des systèmes de gestion de clients (type CRM) et plus encore.
L’analytique (et pas nécessairement les mégadonnées) fait tranquillement son entrée dans le paysage des PME grâce, par exemple, à l’internet des objets qui se démocratise et aux systèmes hyperconvergés. Bref, ce qui est pour l’instant générateur de projets est ce qui entoure l’industrie 4.0 et l’amélioration de leurs opérations traditionnelles. Il ne s’agit pas de mégadonnées dans sa forme la plus simple, mais les méthodes d’analyses qui tournent autour de l’analyse de données machine sont dérivées de pratiques plus complexes, ce qui est intéressant.
Selon notre étude, 24 % des entreprises avaient déjà déployé des outils prédictifs contre 46 % en implantation, et 25 % en planification. Il faut bien sûr faire la part des choses étant donné que 42 % des répondants sont d’entreprises moyennes comptant moins de 500 employés.
Éventuellement, nous arriverons à un point où les technologies seront démocratisées et accessibles même aux entreprises de deux personnes, dans toutes les sphères d’activité. Bientôt, l’agriculteur du coin aura accès à des outils conviviaux qui sont basés sur un historique de données météorologique et des capteurs placés stratégiquement dans son champ. Mais pour l’instant, les entreprises qui n’ont pas de département informatique, ne serait-ce qu’une seule personne, ne se lancent pas dans l’analyse de données.
Plusieurs freins à l’adoption
Vers 2013, les technologies Big Data ont commencé à se démocratiser au-delà des géants de l’internet à la Google et Yahoo!. Déjà, les experts du domaine mettaient en garde les entreprises contre les risques d’échec et les défis d’un projet Big Data. Cinq ans et des centaines de retours d’expérience plus tard, on remarque que c’est généralement les mêmes problèmes qui surviennent.
Une vieille étude de Tata Consultancy Services démontrait que la vaste majorité de ces difficultés à vaincre sont de l’ordre de la culture d’entreprise et non pas des problèmes technologiques[2]. Malheureusement, c’est toujours le cas dans les grandes entreprises où ça ne bouge pas toujours très vite.
Parmi ces défis identifiés par Tata, certains sont encore d’actualité. Notamment, les entreprises se demandent encore où focaliser leurs initiatives Big Data, dans quelles unités d’affaire et sous quelle forme d’organisation. Est-ce que c’est de l’Agile, du DevOps, des équipes pluridisciplinaires? Vient ensuite le problème de faire financer les initiatives Big Data, le recrutement, la formation et autres par la haute direction. Qui devrait payer la chose, les TI, les unités d’affaires? Qu’est-ce que l’on doit dire pour convaincre les gestionnaires du bienfondé du Big Data? Comment on calcule le rendement du capital investi? Une fois que c’est fait, les entreprises se confrontent souvent à un vieil ennemi : la rétention de données. En effet, qu’est-ce qui doit être fait pour que les unités d’affaires partagent leurs précieuses données? Comment est-ce que l’on brise les silos organisationnels? Qui assume le leadership dans tout ça?
D’un point de vue plus local, on observe au Québec d’autres défis, notamment en ce qui a trait aux talents. Il y en a de plus en plus avec une appétence Big Data (malgré les pénuries de main-d’œuvre informatique), mais la vieille garde bien que compétente sur d’autres technologies, n’est pas toujours attirée par ces nouvelles bases de données et langages de programmation, ce qui ralentit assurément l’adoption et l’appropriation. D’ailleurs, selon l’étude, 28 % des sondés considèrent l’embauche et la formation de talents comme étant un des principaux enjeux pour la prochaine année; en d’autres mots, les entreprises manquent de talents pour réaliser ces nouveaux projets c’est pour elles ne devraient pas hésiter à faire affaire avec des fournisseurs de services tels que NOVIPRO.
Ensuite, les initiatives Big Data observées sont souvent menées par le département d’informatique. Le problème ici est que les TI en tant que tels ne sont pas consommatrices de donnée outre celles de leurs systèmes; c’est les lignes d’affaires qui peuvent améliorer leurs processus et l’aide à la décision via une analyse de mégadonnées. Ce qui fait en sorte que parfois d’excellentes nouvelles technologies ne sont pas mises à contribution à leur plein potentiel, car il a peu d’utilisateurs, ce qui contribue au final à donner mauvaise presse à la pratique comme étant surfaite. Les chiffres de notre étude le démontrent d’une certaine façon, car 54 % des entreprises consultent occasionnellement, peu, ou pas les données qu’elles conservent. Ce que ça signifie c’est que plus de la moitié des lignes d’affaire des entreprises sondées n’ont pas inclus dans leurs processus d’affaires une aide à la prise de décision.
On observe également des difficultés au niveau de la gestion du changement. Le Big Data implique qu’à un moment donné, dans un processus d’affaires, une décision sera prise grâce aux mégadonnées qui auront été traitées et transformées en information. On retrouve de la résistance autant sur l’utilisation de ces nouveaux outils qui permettent la transformation des données, que sur la prise de décision en tant que telle. Si l’on n’agit pas sur une information donnée, tout ce qui a derrière en termes d’initiative est gaspillé.
Finalement, le plus gros défi est de trouver ce qu’on fera avec les données : quels sont nos besoins d’affaires et comment est-ce qu’on les développe? Qu’est-ce qui se fait dans notre domaine? Qu’est-ce que nos compétiteurs font et qu’est-ce qu’on devrait faire? C’est le symptôme d’un mal plus profond. C’est-à-dire que dans ce cas, les bases de l’analyse de données, soit l’intelligence d’affaires, la statistique descriptive bête et méchante, ne sont même pas comblés et maitrisées. Il peut s’agir d’un problème d’acquisition et de stockage de données, l’entreprise n’a pas les ressources informatiques nécessaires, il n’y a personne qui s’est penché sur le sujet, etc. On est donc loin de pouvoir se lancer dans de nouvelles activités d’intelligence artificielle! Et si on ne sait pas quoi faire, ce sera difficile de convaincre son patron de la pertinence des mégadonnées.
Même après 5 ans, on est toujours un peu dans cette situation :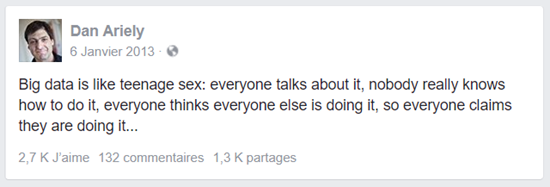
Source : https://www.facebook.com/dan.ariely/posts/904383595868
C’est pourquoi les entreprises ne devraient pas hésiter à oeuvrer avec des accompagnants externes tels que NOVIPRO. Avant de vous lancer sans savoir nécessairement où aller, nous pouvons vous guider dans l’élaboration de besoins et de stratégies que ce soit dans le domaine des mégadonnées, de l’industrie 4.0 ou même de l’internet des objets. C’est seulement une fois que le contexte de l’entreprise sera bien cerné que nous serons en mesure de bien vous orienter sur le type de technologies qui répondront à vos besoins et à cette nouvelle stratégie.
N’hésitez pas à communiquer avec nous pour toutes questions ou idées!
[1] https://www.ic.gc.ca/eic/site/061.nsf/fra/h_03018.html#point2-1
[2] http://sites.tcs.com/big-data-study/big-data-infographic-2/